Tutorial 5 - Training Spiking Neural Networks with snntorch
Tutorial written by Jason K. Eshraghian (www.ncg.ucsc.edu)
The snnTorch tutorial series is based on the following paper. If you find these resources or code useful in your work, please consider citing the following source:
Note
- This tutorial is a static non-editable version. Interactive, editable versions are available via the following links:
Introduction
In this tutorial, you will:
Learn how spiking neurons are implemented as a recurrent network
Understand backpropagation through time, and the associated challenges in SNNs such as the non-differentiability of spikes
Train a fully-connected network on the static MNIST dataset
Part of this tutorial was inspired by Friedemann Zenke’s extensive work on SNNs. Check out his repo on surrogate gradients here, and a favourite paper of mine: E. O. Neftci, H. Mostafa, F. Zenke, Surrogate Gradient Learning in Spiking Neural Networks: Bringing the Power of Gradient-based optimization to spiking neural networks. IEEE Signal Processing Magazine 36, 51–63.
At the end of the tutorial, a basic supervised learning algorithm will be implemented. We will use the original static MNIST dataset and train a multi-layer fully-connected spiking neural network using gradient descent to perform image classification.
Install the latest PyPi distribution of snnTorch:
$ pip install snntorch
# imports
import snntorch as snn
from snntorch import spikeplot as splt
from snntorch import spikegen
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
import itertools
1. A Recurrent Representation of SNNs
In Tutorial 3, we derived a recursive representation of a leaky integrate-and-fire (LIF) neuron:
where input synaptic current is interpreted as \(I_{\rm in}[t] = WX[t]\), and \(X[t]\) may be some arbitrary input of spikes, a step/time-varying voltage, or unweighted step/time-varying current. Spiking is represented with the following equation, where if the membrane potential exceeds the threshold, a spike is emitted:
This formulation of a spiking neuron in a discrete, recursive form is almost perfectly poised to take advantage of the developments in training recurrent neural networks (RNNs) and sequence-based models. This is illustrated using an implicit recurrent connection for the decay of the membrane potential, and is distinguished from explicit recurrence where the output spike \(S_{\rm out}\) is fed back to the input. In the figure below, the connection weighted by \(-U_{\rm thr}\) represents the reset mechanism \(R[t]\).
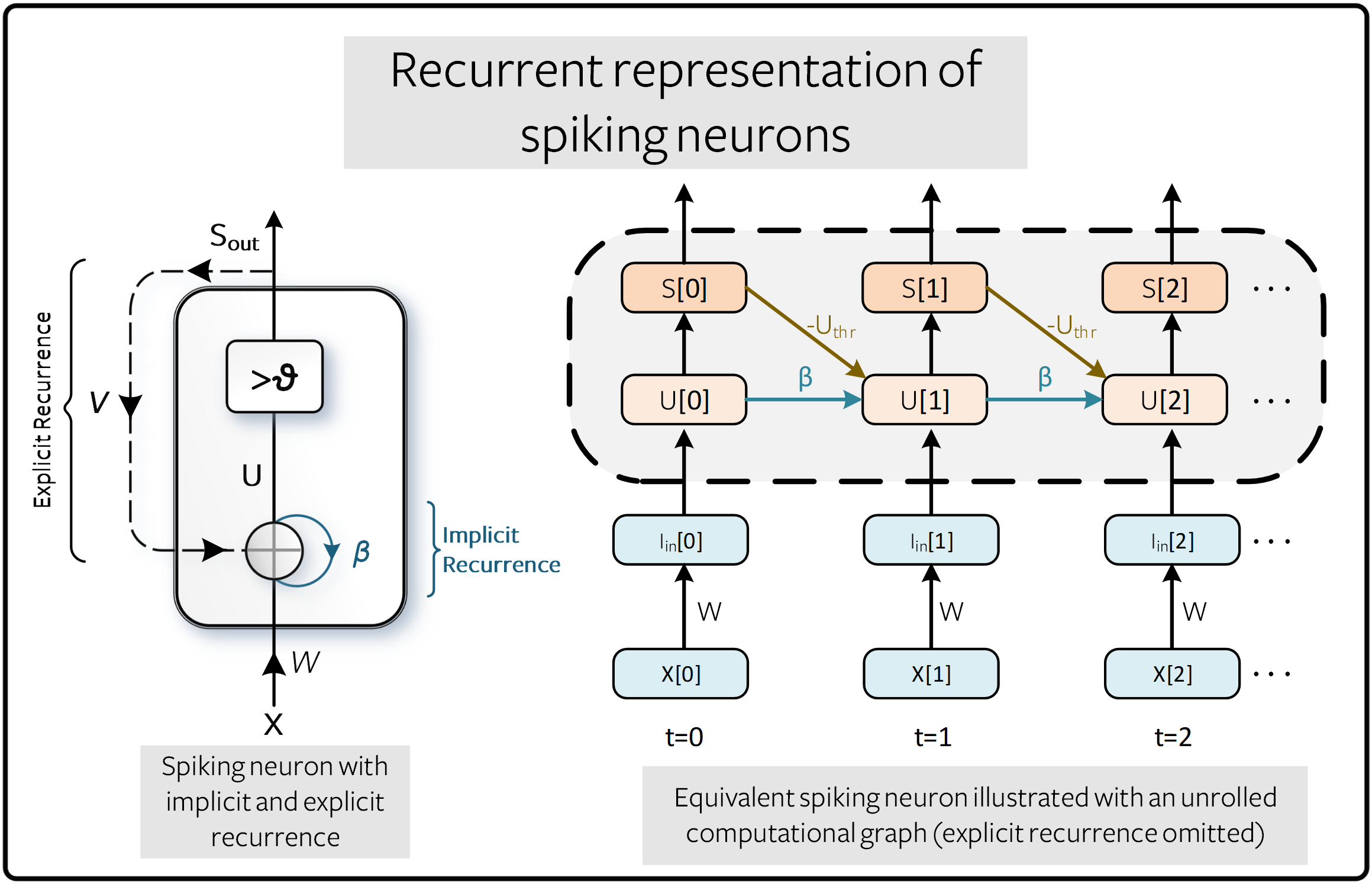
The benefit of an unrolled graph is that it provides an explicit description of how computations are performed. The process of unfolding illustrates the flow of information forward in time (from left to right) to compute outputs and losses, and backward in time to compute gradients. The more time steps that are simulated, the deeper the graph becomes.
Conventional RNNs treat \(\beta\) as a learnable parameter. This is also possible for SNNs, though by default, they are treated as hyperparameters. This replaces the vanishing and exploding gradient problems with a hyperparameter search. A future tutorial will describe how to make \(\beta\) a learnable parameter.
2. The Non-Differentiability of Spikes
2.1 Training Using the Backprop Algorithm
An alternative way to represent the relationship between \(S\) and \(U\) in \((2)\) is:
where \(\Theta(\cdot)\) is the Heaviside step function:

Training a network in this form poses some serious challenges. Consider a single, isolated time step of the computational graph from the previous figure titled “Recurrent representation of spiking neurons”, as shown in the forward pass below:
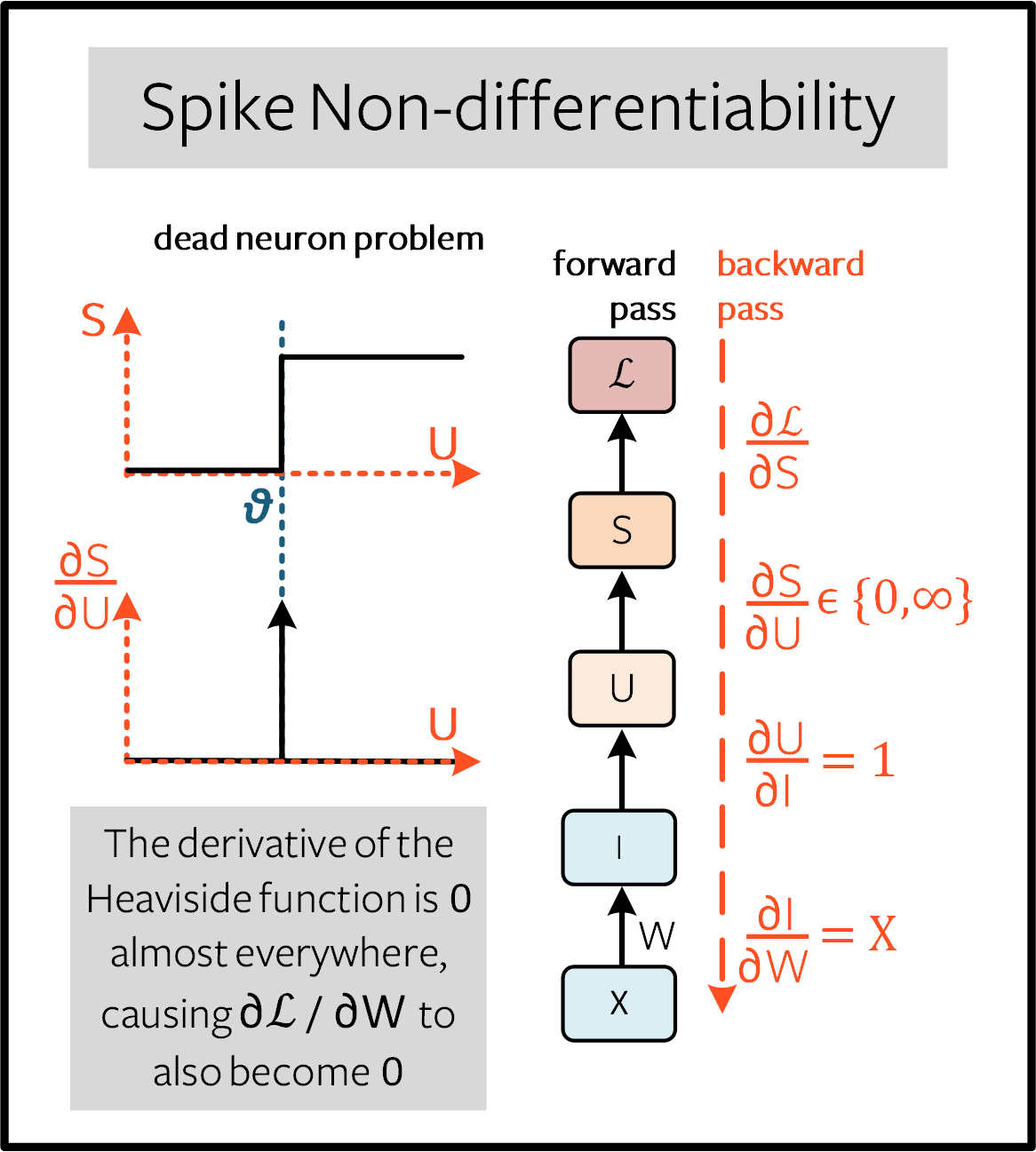
The goal is to train the network using the gradient of the loss with respect to the weights, such that the weights are updated to minimize the loss. The backpropagation algorithm achieves this using the chain rule:
From \((1)\), \(\partial I/\partial W=X\), and \(\partial U/\partial I=1\). While a loss function is yet to be defined, we can assume \(\partial \mathcal{L}/\partial S\) has an analytical solution, in a similar form to the cross-entropy or mean-square error loss (more on that shortly).
However, the term that we are going to grapple with is \(\partial S/\partial U\). The derivative of the Heaviside step function from \((3)\) is the Dirac Delta function, which evaluates to \(0\) everywhere, except at the threshold \(U_{\rm thr} = \theta\), where it tends to infinity. This means the gradient will almost always be nulled to zero (or saturated if \(U\) sits precisely at the threshold), and no learning can take place. This is known as the dead neuron problem.
2.2 Overcoming the Dead Neuron Problem
The most common way to address the dead neuron problem is to keep the Heaviside function as it is during the forward pass, but swap the derivative term \(\partial S/\partial U\) for something that does not kill the learning process during the backward pass, which will be denoted \(\partial \tilde{S}/\partial U\). This might sound odd, but it turns out that neural networks are quite robust to such approximations. This is commonly known as the surrogate gradient approach.
A variety of options exist to using surrogate gradients, and we will dive into more detail on these methods in Tutorial 6. The default method in snnTorch (as of v0.6.0) is to smooth the Heaviside function with the arctangent function. The backward-pass derivative used is:
where the left arrow denotes substitution.
The same neuron model described in \((1)-(2)\) (a.k.a.,
snn.Leaky neuron from Tutorial 3) is implemented in PyTorch below.
Don’t worry if you don’t understand this. This will be
condensed into one line of code using snnTorch in a moment:
# Leaky neuron model, overriding the backward pass with a custom function
class LeakySurrogate(nn.Module):
def __init__(self, beta, threshold=1.0):
super(LeakySurrogate, self).__init__()
# initialize decay rate beta and threshold
self.beta = beta
self.threshold = threshold
self.spike_gradient = self.ATan.apply
# the forward function is called each time we call Leaky
def forward(self, input_, mem):
spk = self.spike_gradient((mem-self.threshold)) # call the Heaviside function
reset = (self.beta * spk * self.threshold).detach() # remove reset from computational graph
mem = self.beta * mem + input_ - reset # Eq (1)
return spk, mem
# Forward pass: Heaviside function
# Backward pass: Override Dirac Delta with the derivative of the ArcTan function
@staticmethod
class ATan(torch.autograd.Function):
@staticmethod
def forward(ctx, mem):
spk = (mem > 0).float() # Heaviside on the forward pass: Eq(2)
ctx.save_for_backward(mem) # store the membrane for use in the backward pass
return spk
@staticmethod
def backward(ctx, grad_output):
(spk,) = ctx.saved_tensors # retrieve the membrane potential
grad = 1 / (1 + (np.pi * mem).pow_(2)) * grad_output # Eqn 5
return grad
Note that the reset mechanism is detached from the computational graph, as the surrogate gradient should only be applied to \(\partial S/\partial U\), and not \(\partial R/\partial U\).
The above neuron is instantiated using:
lif1 = LeakySurrogate(beta=0.9)
This neuron can be simulated using a for-loop, just as in previous tutorials, while PyTorch’s automatic differentation (autodiff) mechanism keeps track of the gradient in the background.
The same thing can be accomplished by calling
the snn.Leaky neuron. In fact, every time you call any neuron model
from snnTorch, the ATan surrogate gradient is applied to it
by default:
lif1 = snn.Leaky(beta=0.9)
If you would like to explore how this neuron behaves, then refer to Tutorial 3.
3. Backprop Through Time
Equation \((4)\) only calculates the gradient for one single time step (referred to as the immediate influence in the figure below), but the backpropagation through time (BPTT) algorithm calculates the gradient from the loss to all descendants and sums them together.
The weight \(W\) is applied at every time step, and so imagine a loss is also calculated at every time step. The influence of the weight on present and historical losses must be summed together to define the global gradient:
The point of \((5)\) is to ensure causality: by constraining \(s\leq t\), we only account for the contribution of immediate and prior influences of \(W\) on the loss. A recurrent system constrains the weight to be shared across all steps: \(W[0]=W[1] =~... ~ = W\). Therefore, a change in \(W[s]\) will have the same effect on all \(W\), which implies that \(\partial W[s]/\partial W=1\):
As an example, isolate the prior influence due to \(s = t-1\) only; this means the backward pass must track back in time by one step. The influence of \(W[t-1]\) on the loss can be written as:
We have already dealt with all of these terms from \((4)\), except for \(\partial U[t]/\partial U[t-1]\). From \((1)\), this temporal derivative term simply evaluates to \(\beta\). So if we really wanted to, we now know enough to painstakingly calculate the derivative of every weight at every time step by hand, and it’d look something like this for a single neuron:

But thankfully, PyTorch’s autodiff takes care of that in the background for us.
Note
The reset mechanism has been omitted from the above figure. In snnTorch, reset is included in the forward-pass, but detached from the backward pass.
4. Setting up the Loss / Output Decoding
In a conventional, non-spiking neural network, a supervised, multi-class classification problem takes the neuron with the highest activation and treats that as the predicted class.
In a spiking neural net, there are several options to interpreting the output spikes. The most common approaches are:
Rate coding: Take the neuron with the highest firing rate (or spike count) as the predicted class
Latency coding: Take the neuron that fires first as the predicted class
This might feel familiar to Tutorial 1 on neural encoding. The difference is that, here, we are interpreting (decoding) the output spikes, rather than encoding/converting raw input data into spikes.
Let’s focus on a rate code. When input data is passed to the network, we want the correct neuron class to emit the most spikes over the course of the simulation run. This corresponds to the highest average firing frequency. One way to achieve this is to increase the membrane potential of the correct class to \(U>U_{\rm thr}\), and that of incorrect classes to \(U<U_{\rm thr}\). Applying the target to \(U\) serves as a proxy for modulating spiking behavior from \(S\).
This can be implemented by taking the softmax of the membrane potential for output neurons, where \(C\) is the number of output classes:
The cross-entropy between \(p_i\) and the target \(y_i \in \{0,1\}^C\), which is a one-hot target vector, is obtained using:
The practical effect is that the membrane potential of the correct class is encouraged to increase while those of incorrect classes are reduced. In effect, this means the correct class is encouraged to fire at all time steps, while incorrect classes are suppressed at all steps. This may not be the most efficient implementation of an SNN, but it is among the simplest.
This target is applied at every time step of the simulation, thus also generating a loss at every step. These losses are then summed together at the end of the simulation:
This is just one of many possible ways to apply a loss function to a
spiking neural network. A variety of approaches are available to use in
snnTorch (in the module snn.functional), and will be the subject of
a future tutorial.
With all of the background theory having been taken care of, let’s finally dive into training a fully-connected spiking neural net.
5. Setting up the Static MNIST Dataset
# dataloader arguments
batch_size = 128
data_path='/tmp/data/mnist'
dtype = torch.float
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("mps") if torch.backends.mps.is_available() else torch.device("cpu")
# Define a transform
transform = transforms.Compose([
transforms.Resize((28, 28)),
transforms.Grayscale(),
transforms.ToTensor(),
transforms.Normalize((0,), (1,))])
mnist_train = datasets.MNIST(data_path, train=True, download=True, transform=transform)
mnist_test = datasets.MNIST(data_path, train=False, download=True, transform=transform)
# Create DataLoaders
train_loader = DataLoader(mnist_train, batch_size=batch_size, shuffle=True, drop_last=True)
test_loader = DataLoader(mnist_test, batch_size=batch_size, shuffle=True, drop_last=True)
6. Define the Network
# Network Architecture
num_inputs = 28*28
num_hidden = 1000
num_outputs = 10
# Temporal Dynamics
num_steps = 25
beta = 0.95
# Define Network
class Net(nn.Module):
def __init__(self):
super().__init__()
# Initialize layers
self.fc1 = nn.Linear(num_inputs, num_hidden)
self.lif1 = snn.Leaky(beta=beta)
self.fc2 = nn.Linear(num_hidden, num_outputs)
self.lif2 = snn.Leaky(beta=beta)
def forward(self, x):
# Initialize hidden states at t=0
mem1 = self.lif1.init_leaky()
mem2 = self.lif2.init_leaky()
# Record the final layer
spk2_rec = []
mem2_rec = []
for step in range(num_steps):
cur1 = self.fc1(x)
spk1, mem1 = self.lif1(cur1, mem1)
cur2 = self.fc2(spk1)
spk2, mem2 = self.lif2(cur2, mem2)
spk2_rec.append(spk2)
mem2_rec.append(mem2)
return torch.stack(spk2_rec, dim=0), torch.stack(mem2_rec, dim=0)
# Load the network onto CUDA if available
net = Net().to(device)
The code in the forward() function will only be called once the
input argument x is explicitly passed into net.
fc1applies a linear transformation to all input pixels from the MNIST dataset;lif1integrates the weighted input over time, emitting a spike if the threshold condition is met;fc2applies a linear transformation to the output spikes oflif1;lif2is another spiking neuron layer, integrating the weighted spikes over time.
7. Training the SNN
7.1 Accuracy Metric
Below is a function that takes a batch of data, counts up all the spikes from each neuron (i.e., a rate code over the simulation time), and compares the index of the highest count with the actual target. If they match, then the network correctly predicted the target.
# pass data into the network, sum the spikes over time
# and compare the neuron with the highest number of spikes
# with the target
def print_batch_accuracy(data, targets, train=False):
output, _ = net(data.view(batch_size, -1))
_, idx = output.sum(dim=0).max(1)
acc = np.mean((targets == idx).detach().cpu().numpy())
if train:
print(f"Train set accuracy for a single minibatch: {acc*100:.2f}%")
else:
print(f"Test set accuracy for a single minibatch: {acc*100:.2f}%")
def train_printer():
print(f"Epoch {epoch}, Iteration {iter_counter}")
print(f"Train Set Loss: {loss_hist[counter]:.2f}")
print(f"Test Set Loss: {test_loss_hist[counter]:.2f}")
print_batch_accuracy(data, targets, train=True)
print_batch_accuracy(test_data, test_targets, train=False)
print("\n")
7.2 Loss Definition
The nn.CrossEntropyLoss function in PyTorch automatically handles taking
the softmax of the output layer as well as generating a loss at the
output.
loss = nn.CrossEntropyLoss()
7.3 Optimizer
Adam is a robust optimizer that performs well on recurrent networks, so let’s use that with a learning rate of \(5\times10^{-4}\).
optimizer = torch.optim.Adam(net.parameters(), lr=5e-4, betas=(0.9, 0.999))
7.4 One Iteration of Training
Take the first batch of data and load it onto CUDA if available.
data, targets = next(iter(train_loader))
data = data.to(device)
targets = targets.to(device)
Flatten the input data to a vector of size \(784\) and pass it into the network.
spk_rec, mem_rec = net(data.view(batch_size, -1))
>>> print(mem_rec.size())
torch.Size([25, 128, 10])
The recording of the membrane potential is taken across:
25 time steps
128 samples of data
10 output neurons
We wish to calculate the loss at every time step, and sum these up together, as per Equation \((10)\):
# initialize the total loss value
loss_val = torch.zeros((1), dtype=dtype, device=device)
# sum loss at every step
for step in range(num_steps):
loss_val += loss(mem_rec[step], targets)
>>> print(f"Training loss: {loss_val.item():.3f}")
Training loss: 60.488
The loss is quite large, because it is summed over 25 time steps. The accuracy is also bad (it should be roughly around 10%) as the network is untrained:
>>> print_batch_accuracy(data, targets, train=True)
Train set accuracy for a single minibatch: 10.16%
A single weight update is applied to the network as follows:
# clear previously stored gradients
optimizer.zero_grad()
# calculate the gradients
loss_val.backward()
# weight update
optimizer.step()
Now, re-run the loss calculation and accuracy after a single iteration:
# calculate new network outputs using the same data
spk_rec, mem_rec = net(data.view(batch_size, -1))
# initialize the total loss value
loss_val = torch.zeros((1), dtype=dtype, device=device)
# sum loss at every step
for step in range(num_steps):
loss_val += loss(mem_rec[step], targets)
>>> print(f"Training loss: {loss_val.item():.3f}")
>>> print_batch_accuracy(data, targets, train=True)
Training loss: 47.384
Train set accuracy for a single minibatch: 33.59%
After only one iteration, the loss should have decreased and accuracy should have increased. Note how membrane potential is used to calculate the cross entropy loss, and spike count is used for the measure of accuracy. It is also possible to use the spike count in the loss (see Tutorial 6)
7.5 Training Loop
Let’s combine everything into a training
loop. We will train for one epoch (though feel free to increase
num_epochs), exposing our network to each sample of data once.
num_epochs = 1
loss_hist = []
test_loss_hist = []
counter = 0
# Outer training loop
for epoch in range(num_epochs):
iter_counter = 0
train_batch = iter(train_loader)
# Minibatch training loop
for data, targets in train_batch:
data = data.to(device)
targets = targets.to(device)
# forward pass
net.train()
spk_rec, mem_rec = net(data.view(batch_size, -1))
# initialize the loss & sum over time
loss_val = torch.zeros((1), dtype=dtype, device=device)
for step in range(num_steps):
loss_val += loss(mem_rec[step], targets)
# Gradient calculation + weight update
optimizer.zero_grad()
loss_val.backward()
optimizer.step()
# Store loss history for future plotting
loss_hist.append(loss_val.item())
# Test set
with torch.no_grad():
net.eval()
test_data, test_targets = next(iter(test_loader))
test_data = test_data.to(device)
test_targets = test_targets.to(device)
# Test set forward pass
test_spk, test_mem = net(test_data.view(batch_size, -1))
# Test set loss
test_loss = torch.zeros((1), dtype=dtype, device=device)
for step in range(num_steps):
test_loss += loss(test_mem[step], test_targets)
test_loss_hist.append(test_loss.item())
# Print train/test loss/accuracy
if counter % 50 == 0:
train_printer()
counter += 1
iter_counter +=1
The terminal will iteratively print out something like this every 50 iterations:
Epoch 0, Iteration 50
Train Set Loss: 12.63
Test Set Loss: 13.44
Train set accuracy for a single minibatch: 92.97%
Test set accuracy for a single minibatch: 90.62%
8. Results
8.1 Plot Training/Test Loss
# Plot Loss
fig = plt.figure(facecolor="w", figsize=(10, 5))
plt.plot(loss_hist)
plt.plot(test_loss_hist)
plt.title("Loss Curves")
plt.legend(["Train Loss", "Test Loss"])
plt.xlabel("Iteration")
plt.ylabel("Loss")
plt.show()
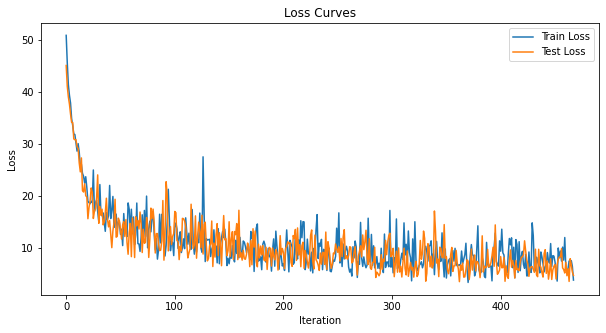
The loss curves are noisy because the losses are tracked at every iteration, rather than averaging across multiple iterations.
8.2 Test Set Accuracy
This function iterates over all minibatches to obtain a measure of accuracy over the full 10,000 samples in the test set.
total = 0
correct = 0
# drop_last switched to False to keep all samples
test_loader = DataLoader(mnist_test, batch_size=batch_size, shuffle=True, drop_last=False)
with torch.no_grad():
net.eval()
for data, targets in test_loader:
data = data.to(device)
targets = targets.to(device)
# forward pass
test_spk, _ = net(data.view(data.size(0), -1))
# calculate total accuracy
_, predicted = test_spk.sum(dim=0).max(1)
total += targets.size(0)
correct += (predicted == targets).sum().item()
>>> print(f"Total correctly classified test set images: {correct}/{total}")
>>> print(f"Test Set Accuracy: {100 * correct / total:.2f}%")
Total correctly classified test set images: 9387/10000
Test Set Accuracy: 93.87%
Voila! That’s it for static MNIST. Feel free to tweak the network parameters, hyperparameters, decay rate, using a learning rate scheduler etc. to see if you can improve the network performance.
Conclusion
Now you know how to construct and train a fully-connected network on a
static dataset. The spiking neurons can also be adapted to other
layer types, including convolutions and skip connections. Armed with
this knowledge, you should now be able to build many different types of
SNNs. In the next
tutorial,
you will learn how to train a spiking convolutional network, and simplify the amount of code required using the snn.backprop module.
Also, a special thanks to Bugra Kaytanli for providing valuable feedback on the tutorial.
If you like this project, please consider starring ⭐ the repo on GitHub as it is the easiest and best way to support it.